
On this page, we will gather all the relevant details and evidence for various topics discussed during the social impact videos.
If you're happy with the level of detail in the videos, you can ignore this page entirely. However, if you disagree with anything that was said, were upset by it, or are just interested to learn more, this will be a good place to get more background on what we've talked about, and why.
In short, this page has three main purposes:
To provide more information and background for people interested in the social impact discussion.
To provide evidence and justification for some of the more controversial claims made in the lectures, when putting that justification in the lectures themselves would derail the narrative too much.
To help you develop a degree of media literacy in these matters. We often find that when we provide sparse references, people misread them, or misinterpret what they mean. Moreover, people will counter with references such as youtube videos about unrelated matters, or articles from unreliable sources. Making a strong point coherently requires reading sources for what they are, and choosing convincing sources for your own arguments. Here we'll take the time to go through the evidence step by step, and to show you how to read different sources dispassionately, and which aspects to treat as evidence and which to dismiss.
This is meant to be a living document, so if you find anything in the slides that you would like to see discussed in greater detail, or if you think there's a position that is unfairly reflected, please get in touch.

Before we get to the details, we'll set some ground rules, and basic policies. How do we choose what to include in these parts of the lectures, and how do we substantiate the claims we make?
To start with, allow me to write a few personal words on why I think it's important to include these topics in a lecture series like this. These videos are the most controversial part of the lecture. I get a lot of support for including them, but also a lot of vehement pushback, including the question why I don't just stick to machine learning.
My answer simple: When using a technology comes with consequences, teaching that technology should include teaching those consequences.
Physics or chemistry teaches many principles that can be used to make weapons. If the teacher is a strict pacifist, they may believe that doing so is a bad thing. This is their opinion, and it has no place in their lectures. Each student should be able to decide for themselves what to use their knowledge for. However, to make an informed choice, the student should have a detailed understanding of exactly what the consequences of that choice are. Here, the teacher does have a responsibility. They should discuss what kind of weapons can be made, which are currently being made, and how they are being used. This is not to tell the students what decision to make, but to help them understand how their decisions impact people: to help them understand what they may be responsible for.
The technologies we discuss in this course can be used to do harm. They can be used to make a variety of weapons, but also things that sound at first much more innocuous. Building a simple predictor for welfare fraud may seem like a beneficial technology, but through various quite subtle mechanisms, such a predictor can end up producing profoundly harmful effects. It's the subtlety of these problems that requires us to delve into these areas so closely: at first sight, the idea is almost always harmless. It takes a little background and insight to see the problems.
Many of you will become programmers. You are the ones who will be asked to build these systems. You are also the only ones who have all the knowledge to understand the potential harm. When push comes to shove, not only do you need to be able to tell people that these problems exist, you need to be able to explain to them what the problem is.

Let's discuss when and why we decide to include a topic.
Clearly, the topic needs to be relevant to machine learning. There may be many topics we feel strongly about, but if they are not relevant to the business of machine learning, they don't belong in a machine learning lecture. Sometimes we need to sketch a larger context, which is not related to machine learning, but within which machine learning plays a small role. In such cases, there should be a clear, unique aspect to the ML part of the case that justifies straying so far from our subject area.
In all cases, we strive to choose subjects that highlight a particular aspect more clearly than any other, similar case. Part of this is often the depth or the extent of the harmful effect, but it also includes particular subtleties such as the difference between intentional and unintentional ethnicity classification, or the specific motivations one might have for building a sexuality classifier.
Third, we require a strong burden of evidence. It may well be that a terrible harm is being done somewhere, but there simply isn't enough evidence to properly substantiate it. In such cases, more investigation is usually called for, and the matter cannot be overlooked, but for us the burden of proof is greater than that of your average news service. In a course with this many students we should stay away from controversial subjects that are too clouded in uncertainty.
Finally, the choice of what is relevant can't just be left to one person. Such a choice is always subjective, but when challenged, we should be able to show that there is at least a good number of experts on the record stating that these are topics relevant to the field, and ideally worth discussing in lecture rooms. This does not at all guarantee any kind of objectivity or truth. It just guards against an arbitrary inclusion of subjects.

Next, let's look at how we establish fact. In science and math, a single line of evidence is usually usually enough to establish something as true. We can have one carefully designed experiment, or one detailed proof, and the matter is settled. In social matters, things are never so clear-cut. There are always different voices, from many different parties and almost every voice comes with its own biases and backgrounds.
That means that evidence gathering becomes a more messy business. For each kind of evidence, let's see what caveats there are, and how we should interpret it.
Types of evidence
Direct evidence. This is simply direct evidence of a fact. It could include videos or photographs, or satellite imagery. While this type of evidence often seems the strongest, and least easy to dismiss, there are things to be aware of. Consider, for instance, using a single video of a violent police arrest to establish police brutality. The video by itself may be incontrovertible, but in the strictest sense, it is only evidence of one instance of police brutality. This is called anecdotal evidence. To establish a pattern of police brutality, we would need multiple such videos, and we would make a stronger case by adding different forms of evidence like primary data, and eyewitness accounts.
Eyewitness accounts. One subtle form of direct evidence is the accounts of eyewitnesses. Those who have seen or experienced the subject in question. Great care is needed in such cases. The witnesses themselves may be unreliable, have ulterior motives, and even if they are reliable, their evidence may still only be anecdotal. See the next slide for a failure case. In general a witness who is non-anonymous opens themselves up to greater scrutiny, so can be considered more reliable than an anonymous witness (although witnesses often have good reason to remain anonymous). Also,if a witness report appears in a reputable news source, we can be sure that every effort has been made to check the facts of the story. This isn't always possible for every claim, but journalists take great pains to check all elements of a story that can be checked.
Primary data. This refers to statistics from a source that can be trusted to provide reliable and complete data. For instance, in the third social impact video, we look at arrest rates for drug crimes by race. Here, we use the 2013 National Survey on Drug Use and Health [1], a large study commissioned by the U.S. Department of Health & Human Services. It is not impossible that such studies misrepresent the situation. A government institution may be under pressure to provide a better picture of reality, or they may simply make arbitrary mistakes. This is a spectrum. We look for careful studies that are transparent about how data was gathered, and that explicitly detail their own limitations. Note also that when primary data is summarized, for instance in a plot, it can misrepresent the truth if this is done carelessly.
Primary references. Occasionally, the truth can be established directly from the people responsible. Companies will advertise features of their products directly. Countries may publish data that clearly shows certain effects happening.
In addition to primary sources (evidence and references), it can sometimes be useful to insist on secondary sources. These are neutral experts in a domain that have reviewed the available primary sources critically based on their expertise. Examples are large review studies, but also in-depth long-form journalism.
Academic references. These are papers written by researchers, which are peer-reviewed and published in academic journals (or sometimes at conferences). How reliable a paper is as hard evidence depends a lot on the field and on the journal. Some fields, like psychology or medicine require rigid objectivity, and others, like philosophy, history or sociology, allow authors to write from a more personal and subjective perspective. The fact that a paper was peer-reviewed, or that it was published in a reputable journal is not a magic guarantee of truth, although it guards against many problems. As ever, look for papers that are transparent about their process, and will highlight their own limitations. Academic references can produce primary data, or summarise evidence from other sources in a careful reading.
Peer-review is no silver bullet. Many problems have been found in peer-reviewed research that entirely invalidate it. Peer-review guards against some basic problems, but not against everything. In many disciplines, what ultimately matters is whether research is reproducible. Sometimes, this consists of taking the same primary data and repeating the analysis, and sometimes it requires repeating experiments.
Journalistic references. These are articles published in newspapers or other news media. Newspaper articles broadly come in three types: current events, long form journalism, and editorials. Current events are usually intended to be objective but are written as stories develop, so may have limited accuracy. Editorials are explicitly stating personal opinions, so cannot be used as references. The most relevant category here is long-form journalism: long, carefully sourced articles about ongoing events. These will often include a variety of forms of evidence combining original research, eyewitness accounts and references to other sources of evidence.
How do we decide which journalistic sources to trust? Why do we use sources from the Guardian, the New York Times or der Spiegel, but not from Xinhua News Agency, RT or Fox news? Are we showing a left-wing or a western bias in such choices? The first thing to note is that indeed all media are biased to some extent. Whenever we cite journalistic references, we will look for multiple references from across the spectrum. That doesn't mean we can simply allow any article by any source, like Buzzfeed, the Huffington post or Breitbart news. In a news source we look for the following:
A long-term commitment to critical and disinterested reporting. If a news medium has shown itself to be capable of critical reporting against its bias in the past, we may trust (to some extent) that it will do so in the future. When a left-wing newspaper shows itself critical of a left wing political party in its own country, we can take that of a test of its independence. Examples include US media like the Washington Post and the New York Times reporting on the Pentagon papers and the Watergate scandal, the New York Times being sceptical of a staged media tour of Guantanamo Bay, the Guardian reporting on allegations of antisemitism in the Labour party, or the Wall Street Journal's reporting on Trump.
Open, transparent, and honest about limitations. As with the academic references, a good reference bends over backward to give you a stick to beat it with. It will give you everything you need to take the story apart and check for yourself.
A clear separation between the editorial stance (the content labeled as personal opinion) which shows an explicit bias, and the news content, which a good news provider will carefully try to keep free of bias, although some implicit bias may still be present.
Note that references to newspaper articles are almost always a reference to a summary of the evidence. We don't reference the Guardian to say "this is true because the Guardian said so" but to say "this is true because of a variety of evidence, and this article provides a good summary." Of course, presentation of evidence can still be subject to bias, but that is where the above points come in. We place some trust in the Guardian, but we only trust it not to misrepresent evidence. Under that condition, we can simply read the article and judge for ourselves what the evidence says.
You could allege that the set of sources we trust collectively has a western bias. This may be true, but it is also unfortunately true, that there is a limited number of countries which allow a free and unimpeded press to exist at all. A good source for this is the press freedom index [1], and more generally, the work of reporters without borders. While the countries with high press freedom are not universally western, there is a strong overlap. Ideally, we would cite references from multiple countries and cultures to eliminate bias, but if independent news reporting is limited in a country, we must take that into account.
Considering sources
Next, let's talk about some things to keep in mind in general when reading sources, especially journalistic ones. The elephant in the room is bias. We've already noted that all sources have bias. We should be aware of the bias of a source. Western newspapers have western biases, as well as political (left-and right-wing) biases. Moreover, collators of primary data will have biases, and will be paid from different sources. For instance, the Washington Post is currently owned by Jeff Bezos, so that should certainly inform how we read its content on the US business world and politics. It should not, however cause you to dismiss it as a source, without considering its content. You are academics (or at least studying to become academics), and you should be capable of separating a written argument from the biases of its author.
A biased author can write a coherent argument, and if they do so, it should be challenged on the content of the argument.
As we've said before, a good source will give you a stick to beat it with. It will tell you exactly what its limitations are and where the areas of uncertainty lie. this is a spectrum, of course, but if you really want to dig in, look out for this, and look out for the absence of it.
[1] Results from the 2013 National Survey on Drug Use and Health: Summary of National Findings, SAMHSA, 2013

A final notion to be wary of is false balance (also known as "both-sidesism") This is a subtle, but crucial point, so we'll discuss this in more detail.
Some platforms are happy simply to give both parties to an argument equal time and call it a day. This phenomenon was very prevalent among western news media until recently, and it rightly received a lot of criticism. It is not the job of a journalist or an academic simply to let both parties speak. Both should gather evidence and evaluate it themselves. Being objective doesn't mean never drawing conclusions. Given a collection of evidence, any journalist or academic worth their salt should be able to set a spectrum of reasonable interpretations. Any claim outside that spectrum is not entitled to equal attention to claims that could reasonably be supported by the evidence.
In short, when there is disagreement between to parties, we should certainly look at the arguments provided by both sides. However, we should not just just blindly report those arguments, we should evaluate them ourselves.
This is not just for the sake of efficiency. In social matters there is much at stake, and often unscrupulous parties have a lot to gain by creating confusion. When one party is acting in good faith, and the other isn't, a policy of false balance provides a tremendous advantage to the latter to confuse the issue. In short, false balance can be exploited by people acting in bad faith.
There is substantial evidence that this tactic was actively followed by the US tobacco lobby [1] to sow doubt about the fact that smoking causes lung cancer. More recently the case has been made that the debate around climate change has been similarly manipulated [2]. While no direct evidence of intentional manipulation exists here (as it does for the tobacco lobby), there is certainly evidence that disproportionate media attention has been given to anti climate change positions and articles [3,4]. For many other environmental issues, the same pattern is followed [2].
The conclusion is that false balance is not just erring on the side of showing multiple viewpoints, it is an easily exploitable method of viewing evidence. People acting in bad faith can use it to manipulate the public discussion, and public decision making,. for their purpose. For this reason, insisting on balance is not considered sound academic or journalistic conduct. There is no guarantee that it will lead to the truth, and it is not what journalists or academics are supposed to do. Our job is to look at the evidence. When the truth is clear from the evidence, there is no need to provide "both sides" of an issue with equal attention.
We hold ourselves to this standard within the course: when discussing a controversial topic, we will not simply show "both sides" without considering the evidence. We will tell you what the evidence says. If the evidence is unclear, we will refrain from including the topic, but if one side is easy to dismiss based on the evidence we will not give it undue attention.
[1] Tobacco industry tactics for resisting public policy on health, Y. Saloojee , E, Dagli, 2000, Bulletin of the World Health Organization.
[2] Merchants of Doubt: How a Handful of Scientists Obscured the Truth on Issues from Tobacco Smoke to Global Warming, Naomi Oreskes, Erik M. Conway, 2010
[3] Boykoff, Maxwell T., and Jules M. Boykoff. Climate change and journalistic norms: A case-study of US mass-media coverage. Geoforum 38.6 (2007): 1190-1204.
[4] Boykoff, Maxwell T., and Jules M. Boykoff. Balance as bias: Global warming and the US prestige press. Global environmental change. 14.2 (2004): 125-136.
image source: https://undsci.berkeley.edu/article/sciencetoolkit_04

To show the importance of gathering an abundance of evidence, let's look at a case where this approach to establishing fact failed.
The case is the testimony of Nayirah al-Ṣabaḥ before the United States Congressional Human Rights Caucus in 1990.
At that time, Iraq had just invaded Kuwait, and there were serious questions about human rights violations, including the question of whether he US and other nations should intervene (as they eventually did). Reports began to appear of Iraqi soldiers removing premature babies from incubators and leaving them to die. One of the first reports was in the Telegraph on September 5 1990. An entirely reputable newspaper by the criteria of the previous slide. The story spread and eventually lead to the testimony of Al-Ṣabaḥ.
She testified that during the invasion, she had herself seen Iraqi soldiers take babies out of incubators and leave them to die. The story was then referenced multiple times in debates around the United States decision to go to war with Iraq, culminating in the first Gulf war.
The testimony was initially corroborated by Amnesty International, a non-governmental organization. An organization we would call independent. The testimony was reported by various reputable newspapers, like those in the previous slide, and those we use for reference in the social impact videos. Some placed caveats on their reporting, like the Washington Post, which noted that the stories could not be corroborated, due to the lack of access to the occupied territory.
This testimony was later discredited, and it was found that she was the daughter of the Kuwaiti ambassador to the US. Amnesty international retracted its support for the claim, and multiple investigations found that the removal of babies from incubators never happened.
This has nothing to do with machine learning, but it shows an important failure case of our method. Had we applied it in 1990, would we have been fooled? Would we have stated that there are human rights violations happening in Iraq as fact? Let's look at what kind of evidence we might have included to save ourselves from such a mistake.
The main source here is an eyewitness account. It is however, a single account, of a single incident. Even if it's true it may be anecdotal, the witness may have a bias. It is important not to dismiss the account on this basis. We must simply accept our uncertainty. In the face of such uncertainty, you may still believe that military intervention is the right action, but we must be careful about what we call fact.
The story was reported by multiple reputable news sources, but they largely reported the testimony, rather than the facts of human rights violations. A good journalist will apply the principles of the previous slide and report carefully. This didn't always happen. The story of the incubators was reported as fact in the Washington Post, for instance [1]. The key thing to note is that this was done in an editorial. It's still a failure of the Post when something stated as fact anywhere turns out to be untrue, but we can be more careful by ignoring the editorial content. Another article [2] from the same time is less of an editorial and more of a long-form article. It summarizes the available evidence into a narrative, which may be biased, but it goes through great trouble to provide sources. Here, we see the claim not stated as fact, but backed up by sources, and evaluated for veracity. The article explicitly states that the claim cannot be independently verified, and the conclusion of the article leans more to a propaganda war, than outright human rights violations.
The other forms of evidence, such as direct evidence, primary data, or academic sources were not available. This doesn't mean that the story is definitely untrue: there are good reasons for such evidence to be absent. We should not dismiss the story, we should simply accept a degree of uncertainty about its veracity.
The Nariyah case is a good example to keep in the back of your mind when evaluating evidence. When the stakes are high, and the interests of international corporations or nation states are involved, we are not just dealing with objective evidence gathering, we are gathering evidence in the face of adversarial actions. Institutions that are actively trying to muddy the waters for their own benefit. As we see in this case, such institutions can include parties in the United States.
[1] Hoagland, Jim (September 25, 1990). End Saddam's reign of Terror. Washington Post
[2] Glenn Frankel (September 10, 1990) Iraq, Kuwait, waging an old-fashioned war of propaganda. Washington Post

One good place to learn about sourcing is wikipedia's sourcing policy: https://en.wikipedia.org/wiki/Wikipedia:Reliable_sources
Wikipedia is filled with conflicts between editors, and in order to find consensus, they've developed a coherent idea of what a reliable source is. Their policy is, of course, much more detailed than ours, and contains many interesting insights for different domains that we don't cover.
Understanding science 101 is a resource developed by Berkeley university specifically to help with media literacy in scientific result. the picture in the slide on false balance above was taken from this series. Reading scientific evidence is a difficult task: the scientific process is rife with pitfalls and perverse incentives of which you should be aware. However, that doesn't mean that any scientific result can simply be dismissed out of hand. Figuring out what is true requires some understanding of the process.

In the first social impact video we talk about social impact in general. Since this is an overview, many topics are discussed briefly and without great detail. We'll try to add some background for the topics of the Xinjiang conflict, the COMPAS parole prediction system and the general topic of gender classification.

The most contentious claim made in this video is probably that there are human rights violations taking place in the Xinjiang region in China. I am stating this as fact, not as an opinion or something reported by somebody else. As we saw with the example of the Nayirah testimony, it's easy to go wrong in such cases, even if you rely on both eyewitness accounts and reputable, independent news sources. We'll go through the available evidence category by category.
To substantiate the claim in the slides, we will focus on two specific claims about the Xinjiang situation:
There is mass incarceration, commonly without trial and for extremely innocent behavior.
There is a program of forced birth control. Either through sterilization, fitting of IUDs or abortion.
In both cases, ethnic groups like Uyghurs and Kazakhs are specifically targeted. While there are many more aspects to this issue, these are the two claims for which there is ample evidence, even when discounting eyewitness reports and reports by potentially biased media. That is, even the most sceptical reading of the evidence should lead to the conclusion that these two claims are true.
While there is no universal definition of what constitute human rights, freedom from arbitrary incarceration and bodily autonomy should be uncontroversial to include.
Let’s look at some of the evidence for what is happening in Xinjiang.

One form of direct evidence we have are western media tours of the facilities, which often paint a relatively pleasant picture [1,2]. We must obviously take these with a grain of salt. A key aspect of the claim we're evaluating is that the Chinese state is hiding these abuses. In that light, a carefully choreographed tour of a very specific facility provides limited evidence, although it does show that at least some Uyghur people are willing to make statements like these on camera.
On the other hand, the presentation of a video such as [1] is often quite dramatic, using evocative imagery and dramatic music. This is a clear and unambiguous injection of bias by the BBC, and we must be wary of it. If we are looking for incontrovertible evidence, edited video narratives like these (whatever the message) have little value. For that reaosn, we will limit ourselves to written sources only.
A second form of direct evidence is leaked government papers. One particularly strong example is the Xinjiang papers [3], 400 pages of government material leaked to the New York Times. Again, we can be sceptical of the NYT's bias, and of their interpretation of the source material. However, it is crucial to note that the Chinese government confirmed that these papers are authentic. They only allege that they are taken out of context and poorly translated, which we may doubt, but we must accept that these are not fake documents. For our purposes, the main thing the Xinjiang papers show is the scale of the project (single facilities housing tens of thousands of people), resistance within the government against the program (specifically an official named Wang Yongzhi, who built two of the facilities, resisted and was then sent to prison) and the fact that inmates are detained involuntarily and without a criminal sentence (this appears in a Q&A for people speaking to families of detainees in the city of Turpan).
Another form of direct evidence is satellite imagery. This cannot show us what is going on in the camps, but it can at least provide a sense of the scale of the problem. Here, we can show how it is easy to jump to the wrong conclusion. For instance, many observers have noted the barbed wire on the walls of these facilities. This may be more innocent than it seems. Many of these facilities were converted from schools, and it is common in China for schools to have barbed wire on the walls.
We must also be wary of source bias here. One of the more reputable reports using satellite imagery to identify internment sites [4] was produced by the ASPI, an Australian think tank funded by parties in the Australian and US defense industries. Clearly, such an organization may have an incentive to stoke up tensions between nations like Australia and China. However, just because a source has a bias, doesn't mean we can dismiss its evidence out of hand. If the evidence is credible, carefully sourced and dispassionately presented, we must judge it on its own merits. The nitpicking over the details of such reports is too technical to go into here, but if you trust these sources, the main thing that they show is that there are hundreds of internment sites, and that there is a range of facilities from low to high security, with only very specific facilities shown in media tours.
Both the Xinjiang papers [3] and an analysis of satellite imagery by the BBC [5] show that most such facilities can hold at least 10 000 people (assuming each inmate has their own cell), with the upper end of the estimate at 100 000. This suggests that the commonly alleged figure of around 1 million people detained is highly credible (some other means of estimation arrive at the same number, but we won't delve into them here).
When it comes to eyewitness accounts, we must be careful not to make the same mistakes made in the Nayirah case. We consider the case here to be much stronger for three reasons.
1) There are many more eyewitness reports. [6,7,8] in particular provide relevant evidence of arbitrary incarceration, and forced birth control. For extensive collections of victim accounts, see the Xinjiang victims database [9], the Xinjiang documentation project [10], and a recent 160-page Amnesty international report [11]
2) There are eyewitness reports from different sides. Not just from camp inmates, but also a police detective [12,13], teacher [14] and a gynaecologist [15] previously employed at the camp.
3) The stories told by eyewitnesses are consistent with one another, and corroborated by primary data.
These are clearly also journalistic sources. We will assume here that reporters faithfully described what witnesses reported and focus on the reliability of the witnesses themselves. The reliability of the news media themselves, we will deal with below. Many of these accounts are not independently verifiable, but the vast amounts of consistent witness testimony from different sides, tells us that we are dealing with a very different situation from the Nayirah case.
There is obviously little primary data coming out of China directly, but a programme of this size is difficult to hide.
The main source of information for our purposes, is the birthrate in Xinjiang province. According to official Chinese statistics, it has halved between 2017 and 2020 [17,18]. Note that a) this was from an already low starting point, and b) the drop is concentrated in areas with high Uyghur concentration like Hotan prefecture. This drop is not denied by the Chinese state, so we can take it as a rare point of agreement. We will discuss the official explanation below.
Procurement bids, the procedure by which companies acquire contracts for delivery of goods and construction of buildings, are another source of primary data. Many of these are or were publicly available online. Because they reference specific locations, they corroborate that at least some of the sites shown are indeed internment facilities, sometimes requiring high-security equipment such as riot batons. They can also be used to arrive at an estimate of about 1 million people incarcerated, as done in [16].
In 2022, a hack called the Xinjiang Police Files [30,31] revealed a massive cache of information, including images of detainees, and the acts they were detained for. It corroborates that detainment is not voluntary, and that it is for trivial activities such as growing a beard, or studying scripture.
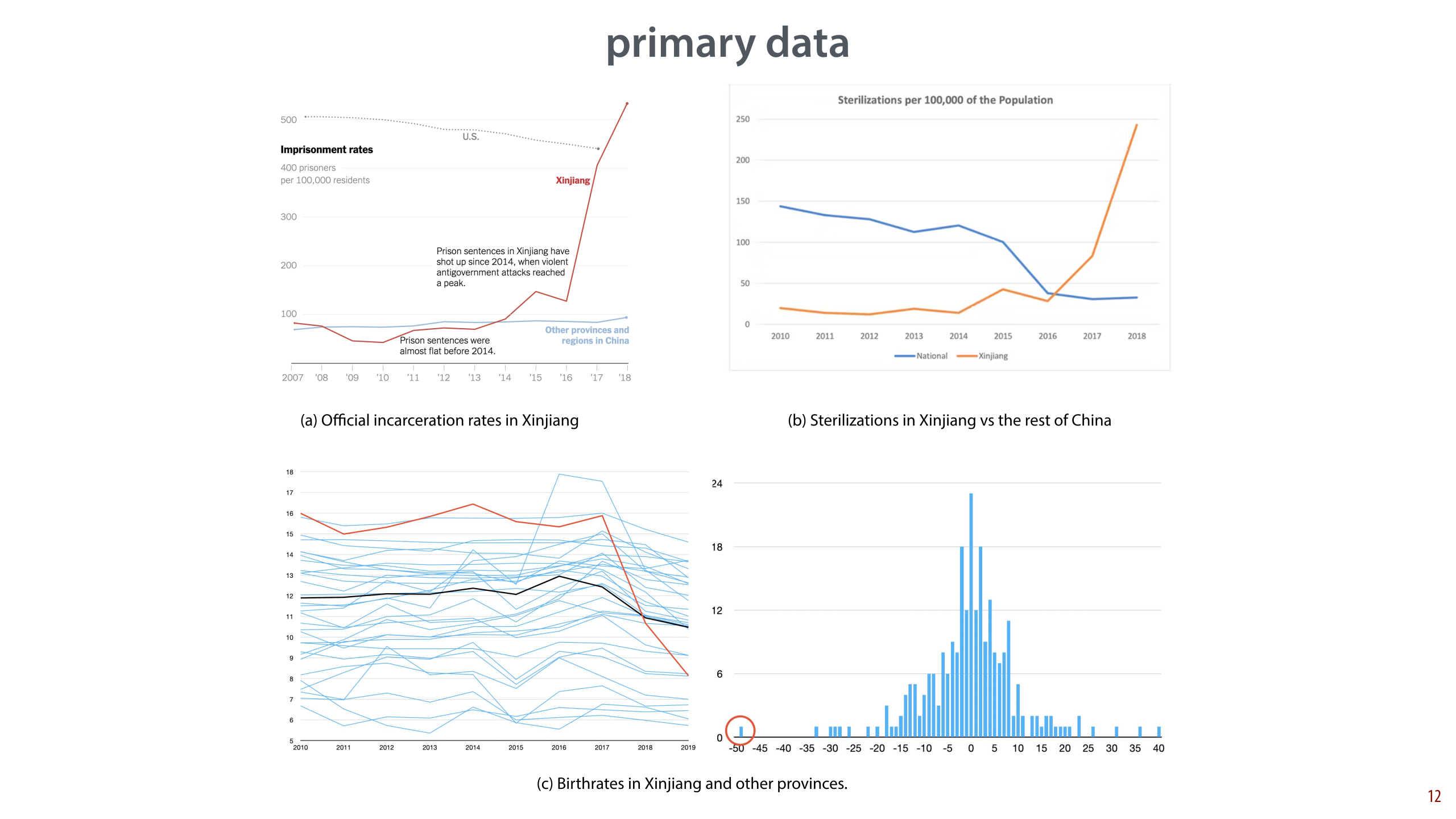
On the slide are some graphs of these data:
a) Official incarceration rates in Xinjiang compared to the rest of China and to the US. Note that this is only the official number of 230 000 people imprisoned. Note also that while this figure is from the NYT, the data is official government data.
b) Sterilizations in Xinjiang vs. the rest of China. From [Zenz 2020], can be verified with this data.
c) Left: Xinjiang's birthrate (red) against other provinces (blue), and the Chinese average. Note that the vertical axis does not start at 0, somewhat amplifying the effect. Right: all two year-changes for all provinces as a histogram, with Xinjiang circled. From official government data. From this twitter thread. Similar plots are available in [Zenz 2018] and the AP report, but these do not include 2019.

There is limited academic work on Xinjiang and, unfortunately most of it is not peer reviewed and comes from sources with highly biased funding (one way or the other). We present some examples here, but in general, this case cannot be well built on academic references alone. Note that we can still build a much stronger claim based on the direct evidence cited in these papers: we just can't take their word for it that their readings are always correct.
Two commonly cited researchers on either end of the spectrum are Adrian Zenz [16,17] and Li Xiaoxia [18]. Zenz is an anthropologist funded by the right-wing think tank the Victims of Communism Memorial Foundation. Li is the director of the Ethnic Studies Institute of the Xinjiang Academy of Social Science. Zenz's work is regularly cited in Western media and Li's work is regularly cited by Chinese state media. In both cases, there is plenty of reason to doubt the independence of the researchers a priori, given their funding source. However, we are committed to judging arguments on their own merit, and not purely on the possible biases of the author.
In [16] the main message is the existence and the extent of the camps, based on publicly available procurement bids. Reproduction of these results requires speaking Chinese, and access to data that is now no longer online. Here is one such effort that concludes that the paper is not perfect, but the main message stands.
For our purposes, [17] and [18] are most relevant. Neither appear to be peer-reviewed, but they are at least written in academic style. They both focus on the halving of the Xinjiang birth-rate in the years of 2017-2019. Note that nobody contests this drop: this is taken from official government yearbooks, and confirmed by the Chinese government.
Briefly summarized, Zenz alleges that this is due to some form of forced birth control, and Li counters that it is due to a voluntary commitment to official planning policy due to policies instituted by the Xinjiang government. Li's argument can be dismissed on several points, but primarily on the basis that the drop is far below the level we would see if everybody followed family planning policy. We can also note that according to [Wang 2018], birth rates in all but one prefecture in Xinjiang were already well below 2.0 before the drop, having dropped slowly over the previous decades (at 2.56 in 2000 and 1.53 in 2010). This shows 1) that family planning incentives were already in place and taking hold, and 2) that such incentives lead to a slow drop over decades, not a halving in the space of 2 years.
Another rebuttal is [19], a white paper directly from the Chinese government. Note that white papers are different from academic publications, because they are not peer-reviewed. This paper points to a a decade-by decade increase of the total population of Xinjiang. This is to be expected, due to population momentum. That is, these numbers are not a counter-argument to the accusation that the birth-rate has halved over two years in Xinjiang. The birth rate drop would manifest itself much later in the population numbers. Year-on-year birth rates, though available are not given in the report. Many other claims are left unsubstantiated.
[17] has been criticised for various incorrect claims and mistakes in its analysis, and some of this criticism appears to be valid. Zenz is a controversial figure, and perhaps not the best example of academic rigour. However, his work is a central part of the discussion, so we shouldn't ignore it. To save us from having to dig into the nitty gritty details, we can note that the following conclusions from this report can be reproduced independently based on official government data only:
The birth rate in Xinjiang has dropped by half over the span of two years. This is unprecendented anywhere in China in the preceding 20 years.
The number of birth control procedures is substantially higher in Xinjiang than in any other region of China and withing Xinjiang, substantially higher in regions with a larger Uyghur population, such as Hotan prefecture.
In these two years, the number of sterilizations (as opposed to birth control by IUD) in Xinjiang has spiked very strongly while diminishing in the rest of China.

There is a wealth of journalistic sources, that largely carefully summarize the above evidence, and sometimes add some of their own. The following is a relatively arbitrary selection from different countries, and different parts of the spectrum. These are all from western, or western-influenced countries, but they are also all media with a strong commitment to independent and unbiased reporting, and a clear separation of editorial and journalistic content.
Some of these contain original research, while others report on documents and findings already mentioned elsewhere, such as [19], which reports on the ASPI findings in [4]. This latter category is relevant because it shows an independent journalist has gone through the report, looked at it critically and offered a voice to all relevant parties.
The Guardian (left-leaning, UK) [6] provides an in-depth report from a former camp inmate. [20] reports on the release of [4].
Wall Street Journal (right learning, US) [21, 22, 23]
Frankfurter Allgemeine Zeitung (right-leaning, Germany) [25]
The New York Times (left-leaning, US) [3,26]
Le Figaro (centre-right, France) [27]
AP (independent news service): [28] reports on [17] and adds statements from relevant parties, including witnesses. [29] reports on an original, corroborated leak of government papers, showing religion, not extremism as a primary reason for detention.

So, can we conclude that there are human rights violations? Even if we take the kindest reading of the situation, based entirely on official data from China, there are at least 230 000 people incarcerated in Xinjiang, a proportion of about 5/1000. This is a little higher than the US national incarceration rate, the highest in the world, which already regularly invites suggestions of a human rights violation. Compared to the rest of China, the number is extremely high, and, most importantly, it has shot up in only two years since 2016. Seen figure (a) in the next slide.
If we add to the evidence satellite imagery, procurement bids, and leaked data confirmed as authentic, we see that an estimate of more than 1 million people incarcerated (about 1/25) is much more likely. At such a scale it is difficult to imagine the incarceration is all for serious crimes, and based on careful trials. The eyewitness accounts overwhelmingly show that the simplest offences like gathering at home with multiple people, having a family member take part in a demonstration abroad, or having Whatsapp on your phone are enough to be incarcerated for multiple years. If you want to discount all witness evidence, there are still leaked documents like the Turpan Q&A [3], which explicitly prepares officials for encounters with family members, stating inmates aren't criminals, but may not come home until they're "cured".
Second, the unprecedented drop in birth rate, coupled with a spike in sterilizations, which cannot be explained by voluntary family planning. By itself, the primary data do not tell us where this drop comes from, although we can rule out the official explanations. If there is some innocent explanation, it needs to account for the fact that Xinjiang birth rates were already below 2.0 before 2017. We can take as further evidence that in some regions, it is publicly stated policy that those who have more than two children illegally will be sent to a re-education camp if they refuse long-term birth control or a termination of their pregnancy. Since we have established that this can mean years of incarceration, this qualifies as forced birth control.
Even if we dismiss all other evidence and focus purely on primary sources and official government information, we must conclude that there is a program of mass, arbitrary incarceration, and forced birth control. Given this evidence, I consider it valid to state as fact that human rights violations are taking place in Xinjiang. Note that many organizations and nations have gone much further and spoken of genocide or near-genocide based on the same data. What we include in the lectures is very much the most charitable reading of the evidence.
To get to this point, we have ignored a lot of evidence. That evidence now gains in weight: even if you dismissed the witness statements of forced birth control as fabrications, you must now concur that they coincide with a vast, unexplained drop in birth rate. Even you don't believe the witness statements that say that Uyghurs are being detained against their will, or for entirely trivial offences, you must account for a system of complexes that can easily hold 1 million people, explicit government directives to make escape from these facilities impossible, and prescribed Q&A's indicating that inmates are involuntarily held but not seen as criminals.

So, to the more relevant question. If we agree that human rights are being violated in Xinjiang, can we conclude that machine learning technology plays a part in it?
Here, we can work primarily with direct evidence. Our weakest claim is that such technology is being developed, but that it is not necessarily already in production. A stronger claim is that the technology is already in production, and actively being used to detect the ethnicity of people in Xinjiang.
For the first, there is ample direct evidence. As shown in the slides, a great deal of publicly available research explicitly mentions the Han and Uyghur ethnicities as target classes. Much of it from Chinese institutions, but occasionally also from or involving western institutions. For instance, the survey paper we show in the slide is partly from a US university. References [Wang 2019, Hang 2017, Gao 2020, Yijun 2020, Yi 2017] further show that this is an active area of research.
To show that this technology is not just being researched as potential idea, but actively being considered for production, ntoe that there are several patents and other documents outlining technology for explicit Uyghur face-detection, from companies like Alibaba, Huawei, Megvii and other [Zhuo2020, Kelion 2021]. These were uncovered by a US-based research group called IPVM studying video surveillance.
For the second claim, that these systems are already being used in production, the evidence is less direct, and we need to rely on evidence gathered by others. A good overview is given in [8]. This is a journalistic reference, namely from the New York Times. A western paper with a left-wing bias, so let's be careful about what we're claiming here. We are not saying that ethnicity is used in production because the New York Times says so, we are referring to an article that presents a collection of evidence. We trust the NYT not to misrepresent the evidence or lie, but otherwise the evidence should speak for itself.
In this case, the evidence presented by the New York Times is mostly direct. It includes (1) advertising by large companies such as SenseTime and CloudWalk, explicitly mentioning Uyghur face detection, (2) procurement documents from police agencies asking directly for detection of Uyghur ethnicity (3) interviews with 5 anonymous witnesses (4) a database from the company Yitu, seen by the New York Times, of face recognition observations, which explicitly includes the field "rec_uygur".
A second point of evidence is an article by Reuters [Asher-Shapiro 2021] reports on a technical standard, uncovered by IPVM, which details how surveillance data should be segmented by categories including ethnicity. The existence of such a standard directly implies that such features are at least being considered in surveillance data, if not used already.
The second claim is not quite as obviously true as the first, but we have clear evidence from multiple sources, gathered by two separate, reputable news sources. This evidence consists of multiple forms of direct evidence, corroborated by witnesses.

Finally, assume we agree that there are human rights violations in Xinjiang, and that machine learning plays a part in that program. Does this justify including it in the course? Given that Chinese students don't always have the easiest time in the Netherlands, is it fair to put such a spotlight on such a controversial issue? Can't we find similar examples a little closer to home? Is the machine learning aspect a big enough part of this problem to warrant its inclusion?
The Xinjiang conflict by itself, and the acts committed are not machine learning related. If machine learning had not existed, this program would still exist. The only reason we bring it up to set the context for the claim in the previous slide. To understand why ethnicity detection of Uyghur people is so harmful, this context is necessary. In this dossier, we spend a large amount of effort to substantiate the claim we make about the Xinjiang program, but note that in the slides themselves, we only touch on this issue very briefly. Just enough to set the context for the part that is relevant for machine learning.
The use of ethnicity detection is clearly relevant to machine learning. The practice of detecting properties from faces, and its harmful impact, is frequently discussed in the AI community [van Noorden 2020 1, 2]. There are various examples, but detecting ethnicity is the clearest one.
We have dealt in detail with the available evidence, and as we said before, even with a charitable reading of the evidence, there is clear evidence of human rights abuses. There is also clear evidence that machine learning technology is both being developed and being used in production, at scale specifically for the purpose of ethnicity detection.
Next, we should ask ourselves whether there are other cases, perhaps closer to home, that could serve as examples equally well. While there are plenty of examples of implicitly biased machine learning systems, such as the COMPAS system in the US or the child benefits fraud detection system in the Netherlands (both discussed later in the course), none of these are explicitly designed with ethnicity as a target feature. Xinjiang is simply the only place where such a large scale program is set up that actively and openly uses machine learning technology to explicitly detect ethnicity from human faces, and then attaches serious consequences to that detection.
Finally, we should show that there is consensus on this issue among at least a subset of experts. Not because this increases the weight of the evidence: this evidence is simple enough that you can judge it for yourself, which is a much more reliable guide than community consensus. We show this consensus to guard against arbitrary inclusion of of topics.
Our first point comes from the NYT article linked in the previous slide [Mozur 2019]. There, Jennifer Lynch, surveillance litigation director at the Electronic Frontier Foundation is quoted:
“It’s something that seems shocking coming from the U.S., where there is most likely racism built into our algorithmic decision making, but not in an overt way like this. [...] There’s not a system designed to identify someone as African-American, for example."
Earlier, the article summarizes the viewpoints of the interviewed experts as:
“It is the first known example of a government intentionally using artificial intelligence for racial profiling, experts said.”
To broaden our view, [van Noorden 2020] provides a survey of 480 face recognition and biometrics researchers on general ethical implications of face-recognition research. Many questions directly, or indirectly reference the Xinjiang issue. For instance, when asked "Is it ethical to do facial recognition research on vulnerable populations that might not be able to freely give informed consent, such as the Muslim population in western China?" over 70% of respondents answered that such research could be ethically questions, even if consent was given. This shows, to some extent, the widespread concern about these ethical issues in the community.
This is why we chose to include the Xinjiang conflict as a subject. It is simply the only example of a large scale use of intentional ethnicity detection. It is also a rare example of machine learning technology contributing directly to a human rights violation. We don't need to spend much time on it in the course, because there are few subtleties to the way machine learning impacts society here, but it does need to be mentioned.
The Nature article also shows, of course, that there is a strong divide in the community, with many Chinese researchers objecting to the Western narrative of what is happening in Xinjiang. We don't mean to suggest that there is consensus on this issue in the global community, only that it is important enough to discuss in a course like this.

If you're interested in the Xinjiang issue there is a lot more to read. So far, we've included only the references required to make the points we needed to make. For a full understanding of the situation, you'd need to cast a wider net. Here are some places to start.
The history of Xinjiang and modern China.
For non-Chinese students, the history of China in the 20th century is not something we're taught much, but you need some of it to understand how things ended up the way they are. Wikipedia is of course a good starting place for general research, but it's quite a read. The following website provides a more high level overview of how the modern state of China came to be.
https://departments.kings.edu/history/20c/china.html This is probably a bit of a western reading of history, but take it as an overview of the important events.
Xinjiang itself has a rich history and has had various relations to China over the centuries. The region as it's now defined became part of China in 1949 at the end of the Chinese civil war. This was a largely political process. The following wikipedia pages are good places to start
History of Xinjiang
Incorportation of Xinjiang into the People's Republic of China
Data mining in Xinjiang. It's likely that most data operations in Xinjiang are not automated, but simply done by large amounts of manual labourers. The following articles shed some light on how this looks. The first is based on witness statements, the second is based on ASPI research. These are not relevant to the point we need to make, but they do touch on predictive policing, which comes up later in the course.
The Xinjiang data police, Noema magazine, Darren Byler, 8 October 2020
Chinese effort to gather ‘micro clues’ on Uyghurs laid bare in report, the Guardian, Helen Davidson and Vincent Ni, 19 October 2021
Students and lecturers. The following article details the experiences of Darren Byler, lecturing about this topic and interacting with Chinese students. I found it interesting to read how discussing this issue publicly plays out on a small-scale personal level. Unlike me, Byler makes no effort to remove his politics from his lectures, so take that into account when reading the article or watching his lecture (but then unlike me, he has extensive field experience in Xinjiang).
‘Truth hidden in the dark’: Chinese international student responses to Xinjiang, SupChina, Darren Byler, 1 May 2019

General
[1] Inside China's 'thought transformation' camps, BBC News John Sudworth, 2019.
[2] China says pace of Xinjiang 'education' will slow, but defends camps, Reuters, Ben Blanchard, 2019
[3] The Xinjiang papers, the New York Times, Austin Ramzy and Chris Buckley, 16 November 2019
[4] The Xinjiang data project, ASPI, 2019
[5] China's hidden camps, BBC, John Sudworth, 2019
[6] ‘Our souls are dead’: how I survived a Chinese ‘re-education’ camp for Uyghurs, the Guardian, Gulbahar Haitiwaji, Rozenn Morgat, 2021
[7] She survived a Chinese internment camp and made it to Virginia. Will the U.S. let her stay? Washington Post, Emily Rauhala and and Anna Fifield, 2019
[8] Abortions, IUDs and sexual humiliation: Muslim women who fled China for Kazakhstan recount ordeals, Washington Post, Amie Ferris-Rotman, 2019
[9] The Xinjian victims database. Gene Bunin, from 2018.
[10] The Xinjiang documentation project, primary accounts, University of British Columbia
[11] “Like we were enemies in a war”China’s Mass Internment, Torture and Persecution of Muslims in Xinjiang, Amnesty International, 2021
[12] 'Some are just psychopaths': Chinese detective in exile reveals extent of torture against Uyghurs, CNN, Rebecca Wright, Ivan Watson, Zahid Mahmood and Tom Booth, 5 October 2021
[13] Uyghurs tortured and beaten to death in Xinjiang, former Chinese police officer reveals, Sky news, 11 October 2021
[14] Confessions of a Xinjiang camp teacher, The Diplomat [MBFC], Ruth Ingram, 17 August 2020
[15] Gynecologist Exiled From China Says 80 Sterilizations Per Day Forced on Uyghurs, Newsweek [AS], Nicole Fallert , 14 March
[16] ‘Thoroughly reforming them towards a healthy heart attitude’: China’s political re-education campaign in Xinjiang, Central Asian Survey, Adrian Zenz, 2018
[17] Sterilizations, Intrauterine Devices and Compulsory Birth Control: the Chinese Communist Party's Campaign to Suppress the Birth Rate of Uyghurs in Xinjiang, Adrian Zenz, 2020
[18] An Analysis Report on Population Change in Xinjiang, China Daily, Li Xiaoxia, 2020
[19] Xinjiang population dynamics and data, The state council information office of the PRC, September 2021
[20] China has built 380 internment camps in Xinjiang, study finds, the Guardian, Emma Graham-Harrison, 24 September 2020
[21] China’s Xinjiang Crackdown Reaps Millions of Dollars in Assets for the State, Wall Street Journal, Eva Xiao and Jonathan Chen, 24 September 2022
[22] Leaked Documents Detail Xi Jinping’s Extensive Role in Xinjiang Crackdown, Wall Street Journal, Josh Chin, 30 November 2021
[24] Twelve Days in Xinjiang: How China’s Surveillance State Overwhelms Daily Life, Wall Street Journal, 19 December 2017
[25] Keine „innere Angelegenheit“, Frankfurter Allgemeine Zeitung, Julia C. Schneider, 5 April 2022
[26] China Targets Muslim Women in Push to Suppress Births in Xinjiang, New York Times, Amy Qin, 23 September 2021
[27] Ouïghours : de nouveaux «Xinjiang papers» confirment le rôle de Xi Jinping dans la répression, le Figaro, Rozenn Morgat, 2021
[28] China cuts Uighur births with IUDs, abortion, sterilization, AP, 29 June 2020
[29] China’s ‘War on Terror’ uproots families, leaked data shows, AP, Dake Kang, 17 February 2020
[30] The faces from China’s Uyghur detention camps, John Sudworth, BBC News, May 2022
[31] The Xinjiang Police Files, May 2022
Use of AI and ML technology
[Wang 2019] Wang, Cunrui, et al. Expression of Concern: Facial feature discovery for ethnicity recognition. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 9.1 (2019): e1278.
[Hang 2017] Zuo, Hang, Liejun Wang, and Jiwei Qin. XJU1: A Chinese Ethnic Minorities Face Database. 2017 International Conference on Machine Vision and Information Technology (CMVIT). IEEE, 2017.
[Gao 2020] Gao, Shixin, et al. Facial ethnicity recognition based on transfer learning from deep convolutional networks. 2020 3rd International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE). IEEE, 2020.
[Yijun 2020] Guo, YiJun, et al. A survey of multi-ethnic face feature recognition. Proceedings of the 2020 9th International Conference on Computing and Pattern Recognition. 2020.
[Yi 2017] Yi, Lihamu, and Ermaimaiti Ya. Uyghur face recognition method combining 2DDCT with POEM. LIDAR Imaging Detection and Target Recognition 2017. Vol. 10605. International Society for Optics and Photonics, 2017.
[Zhuo 2020] As China Tracked Muslims, Alibaba Showed Customers How They Could, Too, New York Times, Raymond Zhou, 16 December 2020
[Kelion 2021] Huawei patent mentions use of Uighur-spotting tech, BBC, Leo Kelion, 13 January 2021
[Asher-Shapiro 2021] China found using surveillance firms to help write ethnic-tracking specs, Reuters, Avi Asher-Schapiro, 30 March 2021
Relevance to machine learning
[Mozur 2019] One Month, 500,000 Face Scans: How China Is Using A.I. to Profile a Minority, New York Times, Paul Mozur, 14 April 2019
[van Noorden 2020 1] The ethical questions that haunt facial-recognition research, Nature, 18 November 2020, Richard Van Noorden
[van Noorden 2020 2] What scientists really think about the ethics of facial recognition research, Nature, 19 November 2020, Richard Van Noorden

The COMPAS system has become almost a symbol for fairness in machine learning. We don't take much time to discuss it in the slides, so let's show the whole history in more detail here.
COMPAS stands for Correctional Offender Management Profiling for Alternative Sanctions. It was developed by a company called Northpointe (now renamed to Equivant) as a decision support system for (among other things) parole decisions. Its stated aim is to predict violent recidivism in parole candidates.
COMPAS is or has been in production in several US states. It works by producing three different risk scales called pretrial release risk, recidivism risk and violent recidivism risk. These are then combined into a weighted linear function to provide a score for each parole candidate. The precise way the weights are set and the way the scales are calculated is not public information, but features used include: residential stability, employment status, community ties, criminal history and associates, drug involvement, and indications of juvenile delinquency, vocational/educational problems, the person’s age-at-intake and the person’s age-at-first-arrest.
We include the COMPAS system primarily because it was such a watershed moment in the history of predictive systems determining the course of people's lives. The fact that it might be biased is sufficient reason to mention it here. But is it actually biased? Propublica published an in-depth analysis to support their findings [4]. Perhaps unsurprisingly, considering the way science works, others disagreed. This lead to a heated debate on whether the analysis by ProPublica was correct, whether their definition of a biased system was sound and of whether bias was actually the main problem. It's hard to say whether the debate has been conclusively settled by now, but we'll try to answer a few of the main questions.

The original analysis can be found in [4]. [6] is the rebuttal by Northpointe, and [5] is a critique by independent researchers. There is a lot of back-and-forth about various statistical issues. Questions of whether the correct analyses are used and whether the right alpha levels are set and so forth. We'll try to isolate the most important points without getting too bogged down in the details.
Base rates
The first thing to note is that a large part of [4] is taken up with showing that black people are more likely to be labeled high-risk than white people. This by itself is not a indication of a biased system. In the county for which the data was requested, black people are more likely to re-offend than white people [6, Table 3.3]. This is not a racist statement: in a racially biased society, poverty, drug abuse, contact with crime are all correlated with race, and all increase the chance of recidivism. This means that a person getting out of prison and returning to a largely black community has higher chances of recidivism compared to a person returning to a largely white community independent of their own character. Thus, the fact that the system is more likely to assign high risk to black people doesn't tell us that it's biased.
The main statistics to pay attention to, come all the way at the end of [4]. They are confusion matrices for COMPAS on the total data and separated by race.
We've highlighted the false positives and the false positive rates, to show where the problem is. Given that you're black, you are much more likely to receive an incorrect indication of high risk, than if you're white. In [6], Northpointe accuses Propublica of committing a base rate fallacy here. Specifically, they refer to the false positive paradox.
Here is an example of that paradox: imagine you are given a test for a disease with a 5% false positive rate and a 0% false negative rate. This may seem like a reliable test, but if the prevalence of the disease in the population is only 2%, then testing positive actually means you only have a 29% chance of actually having the disease. This is because the base rate is so low, that even though the test seems pretty good, false positives are still very likely. Question 3 in the probability homework shows a classic instance of this problem.
How does this map onto the COMPAS results? Honestly, I'm not sure. The way I read the ProPublica argument is that if it's the case that being black means you have a higher risk of a false positive for recidivism than being white, the system is unfair. The false positive paradox crops up when the base rate is low. Firstly, that's not the case here (the base rates are between 10% and 50% for both groups depending the details of the experiment) and secondly, the false positive paradox leads to increases in false positives for lower base rates. Here the base rate of recidivism is higher for black people, so the false positive paradox should lead to more false positives for white people.

A pretty convincing explanation of the confusion comes from the fact that there are two conflicting definitions of what it means for a system to be fair. This was explained very clearly in [7], in the Washington Post, where the above image comes from (annotations in orange are added by us). See also [10] for a write-up in the Atlantic.
In short, Northpointe defines a key aspect of fairness by saying that given a high risk rating, the proportion of re-offending and not re-offending should be the same, regardless of race. It's hard to argue that this is not a necessary condition of fairness: if the proportions are different, then a high risk rating means something different for black people than it does for white people. As a result, notice that the proportions for re-offending and not re-offending are similar in the medium/high bars for white and black people.
The total size of the bars is different, but this can be explained from the different base rates. It's reasonable to give black people a higher risk score (so long as we're looking only at prediction, not action), because environmental factors mean that the recidivism risk is higher on average for black people.
The key point to recognize is that ProPublica introduces another consideration that is also necessary for fairness. A false positive is an unfair high risk score: the system predicts I'll re-offend but I don't end up re-offending. If such mistakes are made more often for black people than for white people, then the system is also clearly unfair, at least if a high risk score can be detrimental to a defendant. As the ProPublica article shows, in practice this is certainly the case.
The Washington Post notes that this picture clearly illustrates that given a different base rate, we can't satisfy both requirements. If the system will accurately predict more recidivism for black people (following the base rate) and make the same proportion of mistakes in this category for black and white people, then the false positive rates must be different.
This suggests there is a fundamental problem with defining fairness for classifiers. A system cannot be perfectly fair in both ways and follow the natural distribution of recidivism. We either limit the fairness on one or both of our criteria, or artificially set the proportion of people assigned high risk the same for black and white people. The latter would greatly reduce the accuracy of the algorithm (and we can only to it for sensitive attributes we are aware of), and likely disadvantage white people. Note that this is not just a property of automated systems. Parole boards that don't use risk assessment tools like COMPAS also need to make this tradeoff somehow (likely by trading off all three requirements implicitly).

[1] A practitioner's guide to COMPAS core, Northpointe, 2015
[2] A sample COMPAS risk assesment, published by Propublica, 2011
[3] Machine Bias, Propublica, Julia Angwin, Jeff Larson, Surya Mattu and Lauren Kirchner, 23 May 2016
[4] How We Analyzed the COMPAS Recidivism Algorithm, Propublica, Jeff Larson, Surya Mattu, Lauren Kirchner and Julia Angwin, 23 May 2016
[5] False positives, false negatives, and false analyses: A rejoinder to machine bias: [...] Flores, Anthony W., Kristin Bechtel, and Christopher T. Lowenkamp, Fed. Probation 80 (2016): 38.
[6] COMPAS Risk Scales: Demonstrating Accuracy Equity and Predictive Parity, Northpointe, William Dieterich, Christina Mendoza, Tim Brennan, 8 July 2016
[7] A computer program used for bail and sentencing decisions was labeled biased against blacks. It’s actually not that clear, Washington Post, Sam Corbett-Davies, Emma Pierson, Avi Feller, Sharad Goel, 17 October 2016
[8] The Age of Secrecy and Unfairness in Recidivism Prediction, Harvard Data Science Review, Cynthia Rudin, Caroline Wang, and Beau Coker, 31 March 2020
[9] Setting the Record Straight: What the COMPAS Core Risk and Need Assessment Is and Is Not, Harvard Data Science Review, Eugenie Jackson and Christina Mendoza, 31 May 2020
[10] A Popular Algorithm Is No Better at Predicting Crimes Than Random People, The Atlantic, Ed Yong, 17 January 2016

Finally, we discuss the issue of gender classification. This is a far more complex issue than the other two. Before we discuss what we claim and why we claim it, let's make it absolutely clear what it is that we claim. Our key claim is that gender classification is a controversial subject. This claim itself is not controversial: it is clearly borne out by Google's decision to remove the feature from a key API. Our aim with this section of the video is not to convince you that Google was right to do so. We don't claim that, and it's hard to offer evidence for that claim, since it's a largely moral decision.
Our aim here is to discuss the subtleties of the problem. We would like to show what kind of information informs this issue and how one might come to such a conclusion, so that when you make your own decision on whether such software should exist, and that decision may well stop being academic once you graduate, you do not leap to obvious conclusions too quickly.
Why do we feel the need discuss this issue in particular? We do so for two reasons:
We occasionally use gender classification as an example in the course. For instance, in the video we show in the first part. In older material, gender classification is even a running example throughout the course (this has now been replaced by sex classification in penguins). We do this because it's a simple example of binary classification that everybody is familiar with and that has a nice 50/50 class balance. Since we bring up the idea that this problem can be approached with machine learning, we also have a responsibility to mention that this is often seen as a problematic use of machine learning and to explain the very subtle reasons for why that's the case.
In contrast to the Xinjiang issue and the COMPAS system, this is an illustration of the far more subtle issues of social impact that developers of ML impact may encounter. Even if your system doesn't make predictions that directly affect people's lives, it may make predictions that are seen as offensive or harmful in a way that you had never considered. Perhaps you don't agree, and perhaps you will choose to use the predictions anyway. That is your responsibility, not ours. We do however, feel the responsibility to make you aware of the potential issue, so that you can make an informed decision. This use-case is particularly suitable precisely because it's such a subtle issue, it's diffeicult to explain exactly why it can be so controversial, and yet, because we have an example of at least one large corporation deciding not to offer gender classification as a feature.
None of this requires particularly strong evidence. Google's decision by itself is sufficient evidence that the issue is relevant in our community.
While we are happy for everybody to make up their own mind about this issue, the are a few facts that anybody who reads the evidence critically must agree on. It would be disingenuous and unacademic to do otherwise. They are highlighted in the slide.
First, gender dysphoria is a real and serious condition. It has been part of the DSM, the standard diagnostics manual of psychology since 1980 [1]. The exact prevalence of gender dysphoria is difficult to measure, but common estimates range 0.005% to 0.014% for people of male sex and 0.002% to 0.003% for people of female sex [2]. That is, between 1 in 10 000 and 1 in 100 000. However, there are good reasons to assume the prevalence is much higher. Depending on the definition, estimates can range as high as 1 in 1000 [7].
The combination of clear diagnostic criteria and a clear prevalence shows that gender dysphoria is a real condition. Whatever view you hold on gender, this you cannot dismiss.
To show that the condition is a serious one, a common statistic is the increased suicide rate among transgender people already cited in the slides of the video itself. This gives us a hint of how serious the condition can be. For more insight, we can look at qualitative analyses like. For instance, [4] compares the experiences of children with fluid gender identity differentiating between those who persisted in the transgender identity and those who desisted (become comfortable with their biological sex as a gender identity). In [5] the experience of living with gender dysphoria and autism is illustrated (a relatively common co-occurrence). [6] investigates how transgender people experience Many other papers like these are available. In general, it is not difficult to find first hand descriptions of the experiences of gender dysphoric people. They paint a fairly uniform picture of a very serious condition.
The second claim we make is that people who are gender dysphoric, in general, are much better off living according their gender identity. This includes gender reassignment surgery and hormone therapy. Most health organizations recommend this approach, and explicitly reject any approaches that do not affirm a patient's gender identity. For example, [7] provides an overview of statements by US institutions to this effect.
One controversial aspect of the problem is that any psychotherapeutic approaches that are not strictly affirmative, i.e. that don't strictly work by affirming a person's gender identity are often labeled "conversion therapy," in a parallel with the harmful and widely discredited efforts to "cure" people of homosexuality by psychological means. It would be incorrect to say that there is consensus about this in the medical literature. For instance, in [13], the assertion was made, based on survey data, that non-affirmative approaches are overwhelmingly harmful, and in [14] some serious issues with this conclusion are pointed out. Moreover the authors of the latter offer the opinion that "affirmation vs. conversion" is a false dichotomy, and that non-affirmative care may be beneficial in some cases.
This is far outside our remit, and we don't have the expertise to make any claims on this subject. What it does show however, is that experts don't disagree that affirmative care is the right way forward for the majority of cases. The argument is over how much room to leave for exceptions.
This is sufficient to substantiate the points we want to make: gender dysphoria is real, serious and normally substantially alleviated by living according to one's gender identity. Regardless of your opinions on gender in general and the controversial aspects of transgender issues, these are facts. Together they should be enough to convince you of the truth of claim 3: that for some people gender is a sensitive attribute.
That doesn't mean we have proved that you should never use it or predict it in a machine learning application. Whether or not to do that is a moral choice. We cannot make moral choices for you, and we cannot show which is the right choice by evidence-based reasoning alone. The evidence above should however, tell you that for some people the issue is undeniably a serious one.

[1] Diagnostic and Statistical Manual of Mental Disorders (DSM)-III, 1980
[2] Diagnostic and Statistical Manual of Mental Disorders (DSM)-V, 2013
[3] Harvey Marcovitch, ed. (2018). "Gender Identity Disorders". Black's Medical Dictionary (43rd ed.). New York: Bloomsbury.
[4] Steensma, T. D., Biemond, R., de Boer, F., & Cohen-Kettenis, P. T. (2011). Desisting and persisting gender dysphoria after childhood: a qualitative follow-up study. Clinical child psychology and psychiatry, 16(4), 499-516.
[5] Coleman-Smith, R. S., Smith, R., Milne, E., & Thompson, A. R. (2020). ‘Conflict versus congruence’: A qualitative study exploring the experience of gender dysphoria for adults with autism spectrum disorder. Journal of Autism and Developmental Disorders, 50(8), 2643-2657.
[6] Kerr, L., Jones, T., & Fisher, C. M. (2021). Alleviating gender dysphoria: A qualitative study of perspectives of trans and gender diverse people. Journal of Health Services Research & Policy, 13558196211013407.
[7] Health and Medical Organization Statements On Sexual Orientation, Gender Identity/Expression and “Reparative Therapy”, Lambda Legal
[8] Collin, L., Reisner, S. L., Tangpricha, V., & Goodman, M. (2016). Prevalence of transgender depends on the “case” definition: a systematic review. The journal of sexual medicine, 13(4), 613-626.
[9] When Children say they're Trans, Jesse Singal, The Atlantic, August 2018
[10] Ellie and Nele: From she to he - and back to she again, By Linda Pressly and Lucy Proctor, 10 March 2020
[11] Goodman, M., Adams, N., Corneil, T., Kreukels, B., Motmans, J., & Coleman, E. (2019). Size and distribution of transgender and gender nonconforming populations: a narrative review. Endocrinology and Metabolism Clinics, 48(2), 303-321.
[12] https://en.wikipedia.org/wiki/Demographics_of_sexual_orientation
[13] Turban, J. L., Beckwith, N., Reisner, S. L., & Keuroghlian, A. S. (2020). Association between recalled exposure to gender identity conversion efforts and psychological distress and suicide attempts among transgender adults. JAMA psychiatry, 77(1), 68-76.
[14] D’Angelo, R., Syrulnik, E., Ayad, S., Marchiano, L., Kenny, D. T., & Clarke, P. (2021). One size does not fit all: In support of psychotherapy for gender dysphoria. Archives of Sexual Behavior, 50(1), 7-16.

In the second social impact video, we focus mainly on classifiers that infer particular characteristics of personality (criminality, homosexuality) from images of people's faces.
We address two papers specifically. The papers themselves are cited in the video, and the video itself serves as our analysis. We make no claims for which more extensive evidence is required than we give in the slides themselves, so we will focus here only on offering some extra background and context, and on testing our inclusion policy.
[Wu 2016] Wu, X., & Zhang, X. (2016). Automated inference on criminality using face images. arXiv preprint arXiv:1611.04135, 4038-4052.
[Wang 2018] Wang, Y., & Kosinski, M. (2018). Deep neural networks are more accurate than humans at detecting sexual orientation from facial images. Journal of personality and social psychology, 114(2), 246.

Here again, are the inclusion criteria. Both papers we discuss are specifically about classifiers, so they are both relevant to machine learning.
There are many papers presenting work that purports to infer criminality from facial features. We chose [Wu 2016] for various reasons. First, it is a particularly egregious case, with a variety of problems that are illustrative to discuss. Second, the central finding, about the nasolabial angle, clearly illustrates the importance of consider multiple hypotheses for a given conclusion. Third, the paper has been discussed in detail by others [1], which offers both a more detailed treatment of the paper as well as a substantiation of the relevance.
The second paper we discuss [Wang 2018] offers a more subtle case. The paper was widely discussed in the news media [Levin 2017], but there is good cause to suggest that the authors we treated unfairly by some of these analyses. By contrasting [Wang 2018] with [Wu 2016], we hope to show some of the deeper issues that emerge when the more egregious mistakes are not made.
This is important in analysing papers like these. If we discussed only a paper like [Wu 2016], it may appear that if only the authors had been more careful in their research, everything would be fine. If we covered only the backlash to a paper like [Wang 2018], it may appear that we are decreeing that inferring character traits from facial features is morally wrong and such research should never even start. We intend to do neither. Only by digging into the details of [Wang 2018] can we show, hopefully, that there are fundamental issues with this kind of research that are unlikely to be solved by making the analysis more careful. But also, that simply suggesting that this kind of research should be essentially disallowed or always dismissed out of hand, we would be ignoring important issues, such as privacy, that legitimately deserve attention.

Something that is often mentioned in rebuttals to this kind of paper, is that physiognomy is a discredited science. It's a little disingenuous to use this as a standalone argument. Even if people have tried and failed in the past to divine things like criminality from facial features doesn't prove that with modern methods and perspectives we can't do better. In other critiques it's called a pseudoscience. This, again, is not an argument, it's a shorthand for an argument. To make this argument honestly, we should be able to unpack it to its full form.
What we should do, however, is be aware of the mistakes people have made in the past, and be explicit in where our methods differ.In short, we should know our own history, so as not to repeat the same mistakes.
Wikipedia provides a decent overview of the general history of physiognomy. During its heyday in the 17th to 19th centuries, the evidence seems to be mostly based on the personal experiences of respected physicians. In those days, scientific evidence was much less rigorously separated from the reputation of the scientist. Particularly notable is the work of Cesare Lombroso, who attempted to predict criminal tendencies from physical attributes of the face.
It's hard to deconstruct the original research, since there is so little method behind it. In more modern examples, where the inferences are drawn from data, the following are the main criticisms that seem to come back repeatedly.
Confounding details Even if we can predict X from Y, we may not be looking at the features of X that we think we are looking at. The machine learning literature (especially deep learning) is rife with algorithms inferring differences from background details that aren't actually relevant.
Correlation versus causation Even if we are sure that we are looking only at structural details of the face, finding a correlation between a facial feature and, say, a likelihood of committing crime is no indication of the direction of causation. We go into more details in the third social impact video.
Implicit implications This is perhaps the most crucial aspect. By doing research like this, you are at risk of implying that certain actions could be taken. Should people with criminality-associated features be subjected to greater scrutiny? Should they be forgiven more readily because criminality is "in their nature"? While a researcher may claim they are only investigating correlations, a misreading of research can easily read to very harmful policies.
If your research can easily be misread as meaning something you don't mean to imply, there is extra responsibility on you to explicitly steer people away from those implications.

For some extra background on [Wu 2016], we can start with the author's response. This can be found at the end of [1] and in [2].
A large part of this deals with criticism that is not relevant to the main issue we point out in the paper. It is interesting to note that the authors managed to control for some issues that they are accused of. For instance, in section 5 the authors discuss the criticism that the classifier may pick up on the collars of the subjects, which, as can be seen in the slide are white more often for the non-criminal part of the dataset.
Here, the authors not that everything but the face was removed from the image, so this criticism is not valid. They also indicate that they controlled for broad facial expressions (although it's not clear how), but not for the more subtle facial expressions that the classifier seems to pick up on.
This illustrates an important point. In some sense we are lucky that the classifier picks up on such an obvious incidental point here. But the burden of proof is not on us. It's up to the authors to show that what the classifier picks up on are structural features, not incidental ones like facial expression, lighting or shirt collar. If we had been unable to come up with something that the classifier might be looking at, that would not eliminate the possibility that it does. There are many things, like camera noise or ambient color that are imperceptible to us, but that can easily be picked up on by a convolutional neural network.
In short, it's not enough to correct for a handful of potential confounders you can come up with. You have to show what the model is actually looking at to make a successful claim of a physiognomical correlation. If you can't, because the model or the data doesn't allow for it, the claim can't be made.
The second, probably more crucial issue is causality. If you do find a structural correlation between facial features and criminality, it is almost certainly an indication of a social phenomenon like racism or discrimination based on physical attractiveness (so called lookism). It proves nothing about biological predispositions towards criminal behavior. Like any other society, China has its racial divisions, and it's likely that a more sophisticated classifier would end up picking up on the facial differences between Han and the relatively underprivileged non-Han. It would be as racist to infer a causal link here as it would be to infer that black people are inherently more likely to be criminal.

From this, it's a leap to say that there cannot ever be a biological basis for some tendencies that are associated with criminality. There could be more general behavioral tendencies like rebelliousness, anti-socialism or risk tolerance that, in the right circumstance translate to criminal behavior. If these have a partial genetic basis, this may well be correlated with other genetic expressions.
This leads into behavioral genetics, which is another controversial discussion. In progressive circles this is often seen as the first step on the slippery slope to racism or eugenics. In certain conservative circles, this kind of thinking is more accepted. If you're interested in this question, a good place to start is probably the work of Kathryn Paige Harden [3,4], a geneticist who has written specifically on what the facts of genetics mean for progressive viewpoints.
For us, the main takeaway is that our behaviors are in part inspired by our biology, this is undeniably true (as well as very much by our environment). However, machine learning experiments are just about the worst possible way to figure out the truth of what aspects play which role. We cannot dismiss research like this by simply claiming that there is no connection between genetics and "criminality" (or rather behavorial patterns that commonly lead to criminality). We can say that a machine learning experiment is never going to allow us to untangle the confounders, or work out the causal direction

Wang et al is a more subtle case. Their stated aim is better thought through. They control for confounders more carefully. We discuss the paper and the authors' views in detail in the main video, so there is little to add here. Have a look at their rebuttal [5] if you're interested. It shows a lot of the subtleties of the discussion.

[1] Criminal machine learning, Carl Bergstrom and Jevin West, 2017
[2] Wu, X., & Zhang, X. (2016). Responses to critiques on machine learning of criminality perceptions (Addendum of arXiv: 1611.04135). arXiv preprint arXiv:1611.04135.
[3] Can progressives be convinced that genetics matters? Gideon Lewis Kraus, the New Yorker, 6 September 2021
[4] The genetic lottery, Kathryn Paige Harden, 2021
[5] Author note: Deep neural networks are more accurate than humans at detecting sexual orientation from facial images, Michael Kosinski, Yilu Wang,
[Levin 2017] New AI can guess whether you're gay or straight from a photograph, the Guardian, Sam Levin, 2017

The third social impact video focuses for a large part on the question of profiling. Making use of an attribute like skin color in predicting whether or not a person will commit or has committed illegal behavior. And, more importantly, attaching consequences to that action (like increased scrutiny).

In this video, we discuss the issue of profiling in more detail. We specifically highlight two topics:
Racial profiling in the US, based on drug crime
The child benefits welfare scandal in the Netherlands.
In the case of the former, we start closer to home: a profiling incident that was in the news a while ago. The aim is to show that this is not a problem specific to the US. The reason we move to the US is that we find better data there. Not all countries have a clear record of race for their crime statistics (this has ethical benefits and downsides), so in order to make our discussion concrete, and ground it in reliable data, we need to discuss a specific issue (drugs crime) in a specific location (the US). This allows us to be precise in what we are talking about.
This issue shows a very clear example of profiling. The downside is that it's not directly related to AI technology. However, it isn't hard to see how AI technology may be used in combatting drug crime, leading to profiling and systems like COMPAS hint at this possibility. For a more direct example of AI technology being used in profiling, we turn to the child benefits scandal.
We discuss the child benefit welfare scandal for several reasons.
It's a very clear case of how profiling is concretely in ML-based systems. The sophistication of the predictive software used wasn't very high, but it clearly qualifies as ML.
It's an example of largely unintentional profiling (see the first video). The system programmers most likely didn't intend to explicitly to commit profiling, it simply happened mostly unnoticed as a consequence of poorly thought-through design. The larger scandal also shows cases of intentional profiling by people involved, but there is no evidence (that I'm aware of) that this happened at the software level.
It's close to home. This shows that we don't have to look far abroad for cases of machine learning being used to profile people.

The most comprehensive source relating drug use to race (among many other aspects) in the US is the National survey on drug use and health [NSDUH 2013]. The figures are from 2013, but the most recent version [NSDUH 2021] shows that the trands we discuss here have persisted over the past decade.
The figure on the left can be found on page 27. It shows that indeed the rate of illicit drug use among black people is slightly higher than than among white people. The difference is slight, but consistent over the years. The main point we want to make in the video is that this is nowhere near the arrest gap between the black and white population. That is black people are also arrested for posession of illicit drugs than white people, but by a far greater amount.
To validate this, we can look at data from the Bureau of Justice Statistics [BJS]. Slate [Kahn 2015] and Politifact [Eugene 2016] have both separately plotted these figures, and came up with the same figure, sop we can save ourselves the digging through the primary evience. The fiogure on the right is the one from Politico
[NSDUH 2013] National survey on drug use and health, 2013
[NSDUH 2021] National survey on drug use and health, 2021
[Matthews 2013] The black/white marijuana arrest gap, in nine charts, Washington Post, Dylan Matthews, 2013
[Kahn 2015] What It’s Like to Be Black in the Criminal Justice System, Slate, Andrew Kahn and Chris Kirk, 2015
[Eugene 2016] Van Jones: African-Americans don't use drugs at a higher level than whites but "wind up going to prison six times more.”, Politifact, C. Eugene Emery, 2016
[BJS] https://bjs.ojp.gov/
We make the claim that illegal drug use is slightly higher among black people in the US. This claim is true, as shown in the data from the previous slide.
Note that our aim here is the claim that this is not in proportion to the arrest rate. That is, we are not focusing on the fact that there’s a difference, but on how small the difference is. Still, even with such a small difference, there are some subtleties to consider.
In the slide, are two headlines ([Szalavits 2011] left , [Manning 2016] right) that seem to contradict what we said earlier. Let’s look at the details.
One point we make is that just because the prevalence is slightly higher among black people, we cannot simply conclude that all else being equal, a black person is more likely to engage in illicit drug use than a white person. There is ample evidence of things like poverty and depression being greater in the US among black people, all of which could lead to increases in drug use.
If [Wu 2011], reported on in [Szalavitz 2011], the authors analyze data from the NSDUH (2005-2008) but control for factors like age, socio-economic background and population density. The result is that the differences between ethnicities largely disappear. This suggests, as we hint at in the main video, that the reason for the small discrepancy in drug use we observe—the causal connection—is due to one of these factors.
[Manning 2016] is about the NSDUH (2014), whereas the data from the previous slide was from 2013. Has the trend reversed between 2013 and 2014?
Here the issue is more subtle. Sadly, the summary report from this year does not include a graph similar to that in the previous slide. We’ll need to dig out the raw data. Happily it includes the data for 2013 as well, for comparison.
[Szalavitz 2011] Study: Whites More Likely to Abuse Drugs Than Blacks, TIME, Maia Szalavitz, 2011
[Manning 2016] White People Do More Drugs, Black People Serve More Time, Vocativ, Allee Manning Leon Markovitz, 2016
[Wu 2011] Wu, L. T., Woody, G. E., Yang, C., Pan, J. J., & Blazer, D. G. (2011). Racial/ethnic variations in substance-related disorders among adolescents in the United States. Archives of General Psychiatry, 68(11), 1176-1185.

This is page 157 from [NSDUH 2014] (colors added).
The first thing to note is that there are three categories. Whether the respondent has used illicit drugs over their lifetime, in the past year, or in the past month. Only in the last category is the rate among black people higher than that among black people.
The plot from two slides ago uses the “last month” category. The plot from the Vocative article uses the “lifetime use category”. This explains the difference between the two.
What do these conclusions mean for our claims? Not much. Our main point was that to the extent that there exists a difference, it’s negligible. All we have shown is here is that the difference depends a lot on exactly how you define drug use, and that the differences are likely caused by factors like socio-economic background.
[NSDUH 2014] National survey on drug use and health, detailed tables, 2013
The child benefits welfare scandal (de toeslagenaffaire) rocked Dutch politics in 2021. The government fell, just as we were preparing the first version of the third social impact video.
As the details began to emerge it became clear that a part of the problem was what the government called “self-learning algorithms”, and old phrase fro machine learning. There aren’t many explicit claims in the video that we need to defend. We’ll focus primarily on providing some pointers to primary sources, and further reading for those interested.
The main primary sources are
A report based on the investigation by the Autoriteit persoonsgegevens (the authority on personal data) [AP 2020].
The final report of a parliamentary inquiry into the issue [TK 2020],
[AP 2020] Belastingdienst/ToeslagenDe verwerking van de nationaliteit van aanvragers van kinderopvangtoeslag, Autoriteit Persoonsgegevens, 2020
[TK 2020] Verslag Parlementaire ondervragingscommissie Kinderopvangtoeslag Ongekend onrecht, Tweede Kamer, 2020
For further reading (if you read Dutch) I can recommend [Frederik 2021]. This is an extensive reconstruction of the whole affair. It doesn’t discuss the use af automation much, but it shows how almost every first reading of the situation is wrong, and missing some nuance.
[Scheifes 2021] places the scandal in a more general context of algorithmic decision making in the de Dutch government,
[Frederik 2021] Zo hadden we het niet bedoeld, De Correspondent, Jesse Frederik, 2021
[Scheifes 2021] Opening the black box, De Groene, Ilja Scheifens, February 2021

The key issue from our perspective was the use of a “nationality” feature is a prediction model called the risk-classification model (risico-classificatiemodel). This indicator was used to decide whether people would be subjected to further scrutiny. The risk-classification model is described as self-learning, in [TK 2020] and it is explicitly stated that it learns from examples of correct and incorrect requests for child support requests.
Much like COMPAS, there was no fully autonomous decision making, but more of a pre-selection for a human decision-maker. If the risk score was above 0.8 this would automatically lead to an manual check of the request [AP 2020, pg 15]. Nationality is the only feature meantioned in the report. There were apparently “tens” of other features.
Nevertheless, if the risk-classification model was biased in some way, this would still lead to an unequal pressure of scrutiny.
These reports judge that the tax service made illegitimate use of the nationality feature, but they do not indicate whether this actually led to discrimination in practice. In [AP 2020], there is some language that seems to suggest that there was no discrimination, but there are no details on methodology. This may simply mean that there was no intentional discrimination.

We can find some more information about how the algorithnm works. In February 2021, the state secretary sent a letter to the Tweede Kamer containing some extra details about how the model works. From this, we can draw the following conclusions
At some point the features “number of registrations at address” and “number of children at address” were used [TK 2021, p2] These are already features that are likely to show some correlation with ethnicity.
The model uses at least pairwise interactions between features and the data scientists could diagnose the model based on these interactions. [TK 2021, p7] This suggests that it’s more than a purely linear model, like a logistic regression, but also not something like a deep neural net.
The model explicity does not model causality. [TK 2021, p1]
[TK 2021] Kamerbrief inzake Voorstel van het lid Alkaya (SP) om de staatssecretaris van Financiën (Toeslagen en Douane) te verzoeken nadere helderheid te verschaffen over het ontvangen Risicoclassificatiemodel Toeslagen, Tweede Kamer, Alexandra C. van Huffelen, 8 February 2021. Note that there seems to be an issue with the page numbering.

A more recent report is by the Netherlands Institute for Human Rights (College voor de Rechten van de Mens). An independent organization, funded by the Dutch government that investigates various potential abuses of human rights. They requested data from the tax services for the years 2014 and 2018, and looked at the different risk scores for people with Dutch vs. non-Dutch nationality, Double vs single nationality and a recent date of migration.
The elements in the table are percentages. They indicate what percentage of people in that column was subjected to extra scrutiny as a result of a particular process within the tax service.
It’s clear that the level of scrutiny from the model is higher for the non-Dutch, double nationality and recent migration categories. For the 2018 data, the pattern is the same, but less pronounced.
What can we tell from this data? Does this definitely prove that the system is racist or unfair? To that we need to look again at the definition of fairness. In this case we could say that all else being equal, it shouldn’t matter for your risk score whether you’re Dutch or not. But is all else equal? Are the Dutch/Non-Dutch the same in all attributes?
Note that it’s not necessarily a racist position to suggest, for instance, that fraud might have been more prevalent among non-Dutch people. For instance, a large part of the cause the welfare fraud was a scheme whereby increasingly predatory companies would assist parents in requesting daycare compensation for babysitting done by grandparents. This was legal, but only under certain circumstances, and it was easy to fall foul of the rules.
In such a situation, it’s easy to see that the more unscrupulous might target people whose don’t speak Dutch or don’t speak it very well. This would lead to a disproportionate amount of fraud cases among non-Dutch people. Now imagine that the risk model was perfect and fair: this would be equivalent to a model that doesn’t predict anything, and only looks at the actual transactions to see if fraud was committed. In that case, we would still see this kind of discrepancy.
For the purposes of this report, however, it is only necessary to establish that there is a reasonable suspicion of unfair decision making. The institute has judged this to be the case, and that this reverses the burden of proof. It is now (according to the institute) up to the tax service to prove that they did not discriminate.
[CRM 2022] Vooronderzoek naar de vermeende discriminerende effecten van de werkwijzen van de Belastingdienst/Toeslagen, College van de Rechten van de Mens, 2022

Ethics is a subject with a long and deeply philosophical history. To be honest, most of it is pretty academic, and very unlikely to offer any practical answers for you when you come up against a difficult ethical problem in your own work (for instance whether you should help your emplyer build a risk classification model for the tax service).
For this reason, we prefer to focus on social impact of AI rather than things like AI ethics. Essentially, we need concrete guidelines, and we need them in a hurry: ethics is largely focused on the wrong things.
Nevertheless, it’s good to know some of the fundamentals, just so you can know have a constructive discussion. If you are arguing from a consequentialist perspective, and the other person is arguing from a deontological perspective, it’s unlikely that you’ll get anywhere. You should at least be able to recognize such situations.
The three main disctintions (two of which we mention in the slides) are consequentialism, deontology and virtue ethics. We explain the first two in the main lecture, using the example of the classic trolley problem versus the rogue doctor. In a consequentialist view, the doctor sacrificing one person to save five is no different from diverting the trolley to run over one person instead of five. From a deontological perspective, one may count as a greater insult to human dignity.
Virtue ethics seems to be less relevant to AI problems, I suppose because in AI actions are often not taken by a person. Nevertheless, it’s worth adding for the sake of completeness. Virtue ethics is perhaps a slightly more old-fashioned form of ethics. It’s a lot like deontology, but it looks specifically at personal virtues like bravery. The reason of the deontologist is more external, more the application of a moral rule. For instance, in the case of safeguarding human dignity, we are still looking at the effects of an action to some extent. This also goes for the categorical imperative: it’s a deontological principle, because it defines a moral duty we have, but it’s still built around the effect that the rule has upon the world.
In virtue ethics, the moral way to behave is more personal. It includes stoicism and various Buddhist philosophies. For instance the stoic suggestion that we should accept external misfortune calmly is an example of virtue ethics.
Note that these are all examples of normative ethics: ethical systems that aim to describe and classify what counts as ethical behavior in a prescriptive manner. There is also (links to wikipedia):
Descriptive ethics, which a dispassionate and objective study of what people in general find moral. As such it is perhaps more of a sociological discipline.
Applied ethics, which looks at very specific, usual modern and urgent problems, such as abortion.
Meta-ethics, which looks at ethics at a higher level. Asking questions such as whether ethics exists at all in an objective sense, and whether an ethical claim can be said to be true.
Further reading:
[Sinnott 2022] Sinnott-Armstrong, Walter, "Consequentialism", The Stanford Encyclopedia of Philosophy (Winter 2022 Edition), Edward N. Zalta & Uri Nodelman (eds.)
[Alexander 2021] Alexander, Larry and Michael Moore, "Deontological Ethics", The Stanford Encyclopedia of Philosophy (Winter 2021 Edition), Edward N. Zalta (ed.)
[Hursthouse 2022] Hursthouse, Rosalind and Glen Pettigrove, "Virtue Ethics", The Stanford Encyclopedia of Philosophy (Winter 2022 Edition), Edward N. Zalta & Uri Nodelman (eds.)

Causality is an important topic in machine learning. The main conclusion is usually that machine learning methods (with a few exceptions like reinforcement learning) cannot learn causal connections.
If you want to ensure that you do make causal connections, you’ll need to look into causal inference. This requires a lot of assumptions, especially about what the world looks like and what factors you consider. Your causal reasoning will then only be correct if all your assumptions are true, which is a big if.
If you want to get started with this, the book Causal inference in statistics by Pearl et al. is a good place to start.

We do not currently have any extra material for the fourth social impact video. Feel free to contact us if there’s anything you’d like to see discussed here.